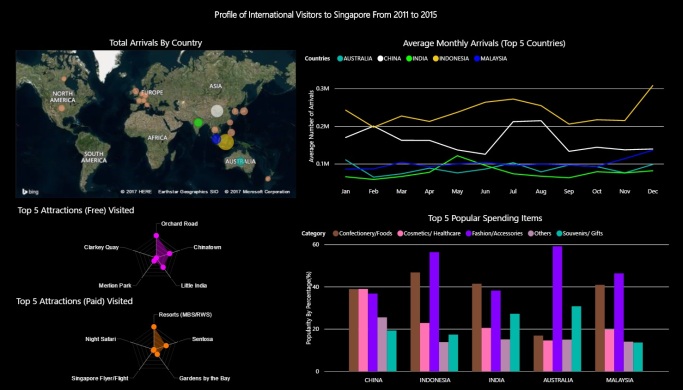
1 Hypothesis
Increasing in the average deal price of Shanghai license plate will increase the number of bidders.
2 Data Exploration
2.1 Background
Over the last two decades, there is an increase in automobile ownership and use in China. This increases energy consumption, worsens air pollution and exacerbates congestion. Therefore, an auction system has been adopted by Shanghai government to limit the number of license plates issued for every month.
The dataset contains monthly auction data from Jan 2002 to Oct 2017. Feb 2008 data is missing, and the number of records is 189 [1].
2.2 Metadata
| Field | Description | Data Type |
| Date | Jan 2002 to Oct 2017 (Feb 2008 is missing) | Date |
| avg_deal_price | The average deal price of Shanghai license plate | Numeric |
| lowest_deal_price | The lowest deal price of Shanghai license plate | Numeric |
| num_bidder | Number of citizens who participate the auction for the month | Numeric |
| num_plates | number of plates that will be issued by the government for the month | Numeric |
Table 1 Metadata
Only variables “avg_deal_price” and “num_bidder” will be analysed in this report.
3 Transfer Function Modelling
Assuming that the relationship between “avg_deal_price” and “num_bidder” is unidirectional, JMP is used for the analysis. Since the hypothesis is increasing in the average deal price of Shanghai license plate will increase the number of bidders, so taking “avg_deal_price” as the input and “num_bidder” as the output.
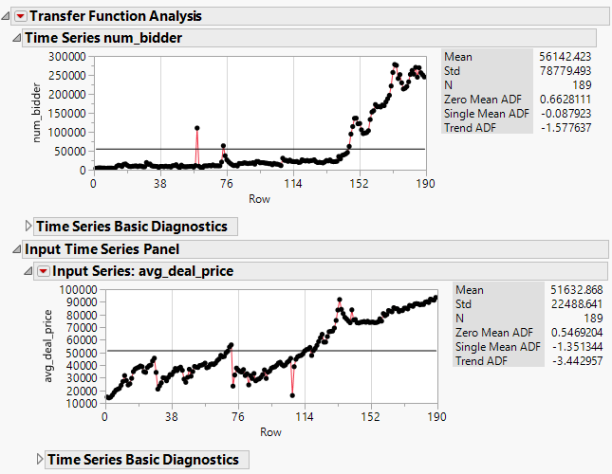
Figure 1 Time series plot of input and output variables
Figure 1 shows that the trends of input and output are both not stationary, so an order 1 differencing is applied to both input and output.

Figure 2 Plot of Input with order 1 differencing

Figure 3 Plot of output with order 1 differencing
Then the trends of input and output become stationary.

Figure 4 Autocorrelation and partial autocorrelation graphs
Since there is no seasonality observed, so ARIMA instead of seasonal ARIMA is applied next to both input and output. Figure 4 shows that there is a distinct drop in the Partial autocorrelation function (PACF) value after lag 3, an AR(3) model is plotted.

Figure 5 AR(3) Model for input
However, Figure 5 shows that the values for AR2 and AR3 in Column Prob>|t| are big. Therefore, AR(1) model is adopted for both input and output instead of AR(3).

Figure 6 AR(1) Model for input
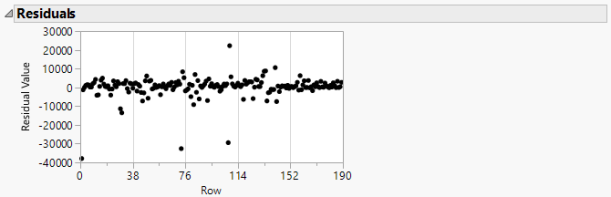
Figure 7 Residuals of AR(1) model for input

Figure 8 AR(1) Model for output

Figure 9 Residuals of AR(1) model for output
Figure 7 and Figure 9 show that the residuals of AR(1) models for both input and output are random.
Next, in order to remove the autocorrelation, pre-whitening is performed to the input variable.

Figure 10 Pre-whitening plot for dataset from Jan 2002 to Oct 2017
Figure 10 shows that there is an increase in the values at both negative lag (lag -14 and -13) and positive lag (lag 1 and 2). This means the cross-correlation is bi-directional. Therefore, the cointegration technique needs to be applied.
4 Bi-Directional Cross-Correlation Analysis
Since the cross-correlation is bi-directional, cointegration analysis with GRETL is performed.
Firstly, a time series plot of both variables is plotted as shown in Figure 11. It shows that both variables values are increasing gradually from the Year 2002 to 2014. Then from the Year 2014 to 2016, there is a big increase in “num_bidder”, but “avg_deal_price” increases in a similar rate as previous years.

Figure 11 Time series plot of both variables from Jan 2002 to Oct 2017
Then the Engle-Graner test for cointegration is performed and the steps are,
Step 1: Determine ‘d’ in I(d) for the first series, where d represents the order of integration and is abbreviated I(d). d is the number of times the series has to be different to be made stationary. ADF unit root test is used to determine d.
Step 2: Determine ‘d’ in I(d) for the second series
Step 3: Estimate cointegration regression: Yt = β1 + β2Xt + εt
Step 4: Determine ‘d’ in I(d) for εt
H0: Unit root (i.e., not cointegrated)
HA: No unit root (i.e., cointegrated)
To perform the ADF unit root test on the residuals from the cointegrating regression to determine the order of integration [2].
4.1 Step 1: Determine ‘d’ in I(d) for the first series
Augmented Dickey-Fuller (ADF) test is performed in Step 1 for series “avg_deal_price”. Taking 6 as the lag order for ADF test which is the cube root of the data size which is 189.

Figure 12 ADF test for series “avg_deal_price”
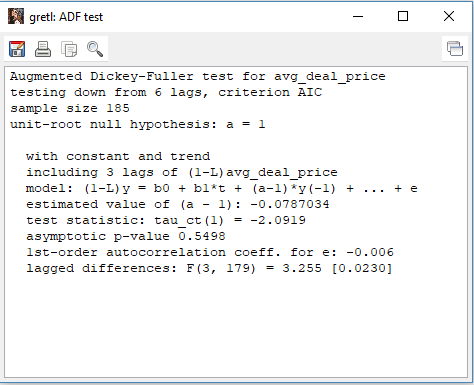
Figure 13 ADF test result for series “avg_deal_price”
Figure 13 shows that the p-value is 0.5498 which is large, hence fail to reject the null hypothesis. Therefore, the series needs to be different to make it stationary. d=1 for “avg_deal_price”.
4.2 Step 2: Determine ‘d’ in I(d) for the second series
The same test is done for series “num_bidder”. Figure 14 shows the p-value is 0.9175 which is large, hence fail to reject the null hypothesis. Therefore, the series needs to be different to make it stationary. d=1 for “num_bidder”.

Figure 14 ADF test for series “num_bidder”
4.3 Step 3 and Step 4
The Engle-Graner cointegration test is performed, taking “avg_deal_price” as the independent variable and “num_bidder” as the dependent variable. Figure 15 shows the result that the p-value is 0.2498 which is not small, hence fail to reject the null hypothesis at 5% level of significance. This means there is no cointegration relation between the two variables.

Figure 15 Engle-Graner cointegration test result for dataset from Jan 2002 to Oct 2017
5 Further Exploration
Since Figure 11 shows that there is a big increase in “num_bidder”, but “avg_deal_price” still increase gradually, this may be the reason that the relationship between two variables is neither unidirectional nor bi-directional. Therefore, data from Jan 2002 to Dec 2013 is going to be analysed instead.

Figure 16 Time series plot of both variables from Jan 2002 to Dec 2013
Firstly, use JMP to perform the unidirectional relationship analysis between two variables as mentioned in Section 3. The result as shown in Figure 17 shows that the cross-correlation is bi-directional. Therefore, GRETL is used to perform bi-directional cross-correlation analysis.

Figure 17 Pre-whitening plot for dataset from Jan 2002 to Dec 2013
Since the number of records is 143, so taking 6 as the lag order for ADF test which is the cube root of the data size which is 143. Following the same steps mentioned in Section 4, the Engle-Graner cointegration test result is shown in Figure 18.

Figure 18 Engle-Graner cointegration test result for dataset from Jan 2002 to Dec 2013
The result shows the p-value is 4.709e-13 which is small, so reject the null hypothesis at 5% level of significance. This means there is cointegration relation between two variables and the series can be written as an error correction model.

Equation 1 Error correction model equation
Equation 1 shows the equation of the error correction model. The residuals from the cointegrating regression are found within the brackets and capture the departure from the attractor from last period. The coefficient gamma is the speed of adjustment, if it is not statistically significant, the variable is weakly exogenous. Before estimating the error correction model, the cointegrating regression is estimated and the residuals are saved.
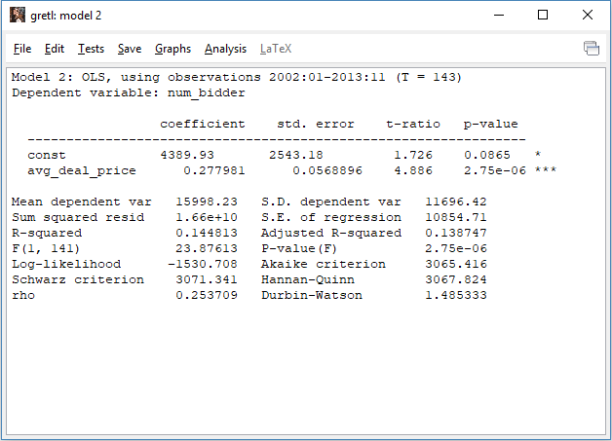
Figure 19 Ordinary least squares method result
Ordinary least squares method is performed to save the residuals. After the residuals are saved, two new series “d_avg_deal_price” and “d_num_bidder” are created that are the difference of the “avg_deal_price” and “num_bidder” as shown in Figure 20. Next step is to estimate the error correction model.

Figure 20 New variables are created

Figure 21 Adding lags

Figure 22 Ordinary least squares method with new variables lagged by 1
To estimate the error correction model, ordinary least squares is applied as shown in Figure 22. The variables are lagged by 1 and remove the “const” is removed.

Figure 23 Ordinary least squares method result with new variables
The p-value of variable e_1 is 8.81e-10 which is statistically significant. This means the dependent variable “num_bidder” is not weakly exogenous and moves to restore the equilibrium when the system is out of balance.
6 Conclusion
From the Year 2014 to 2016, there is a big increase in the number of bidders, but the average deal price of Shanghai license plate increases at a similar rate as previous years. This may be the reason that the relationship between the average deal price of Shanghai license plate and the number of bidders is neither unidirectional nor bi-directional from Jan 2002 to Oct 2017.
However, from Jan 2002 to Dec 2013, there is a bi-directional cross-correlation between the average deal price of Shanghai license plate and the number of bidders. The number of bidders is not weakly exogenous and moves to restore the equilibrium when the system is out of balance.
7 References
[1] “Shanghai license plate bidding price prediction,” 2017. [Online]. Available: https://www.kaggle.com/bazingasu/shanghai-license-plate-bidding-price-prediction.
[2] Janelle, “Cointegration (Video 7 of 7 in the gretl Instructional Video Series),” 17 Feb 2015. [Online]. Available: https://www.youtube.com/watch?v=bJgx3JLb7fI&t=311s.


 Due to the limitation of the transformation, 13 instances of the training dataset where PM2.5 = 0 was removed. Based on the transformation, λ = 0.4 was obtained. Building a new model based on this new transformed dependent variable yielded the results in Table 3, with an adjusted R² of 0.7577.
Due to the limitation of the transformation, 13 instances of the training dataset where PM2.5 = 0 was removed. Based on the transformation, λ = 0.4 was obtained. Building a new model based on this new transformed dependent variable yielded the results in Table 3, with an adjusted R² of 0.7577.

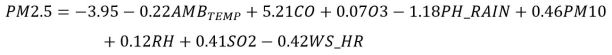
 where n is number of observations, is the actual value, and is the forecasted value.
where n is number of observations, is the actual value, and is the forecasted value.
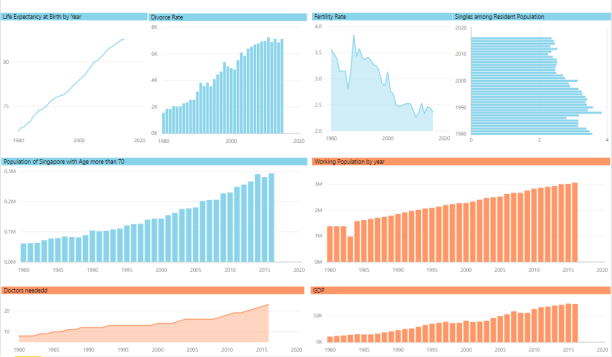
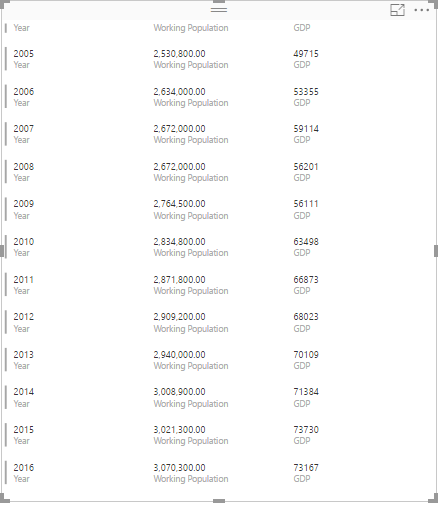
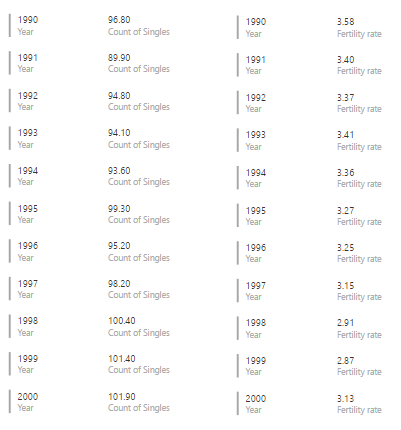









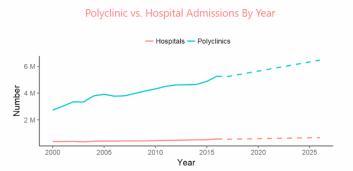

 The shortage of healthcare professionals is expected to keep increasing, and if nothing is done, the shortage of doctors is expected to reach 5504 in 10 years’ time while the shortage of nurses is approximately 9100 in year 2027.
The shortage of healthcare professionals is expected to keep increasing, and if nothing is done, the shortage of doctors is expected to reach 5504 in 10 years’ time while the shortage of nurses is approximately 9100 in year 2027.